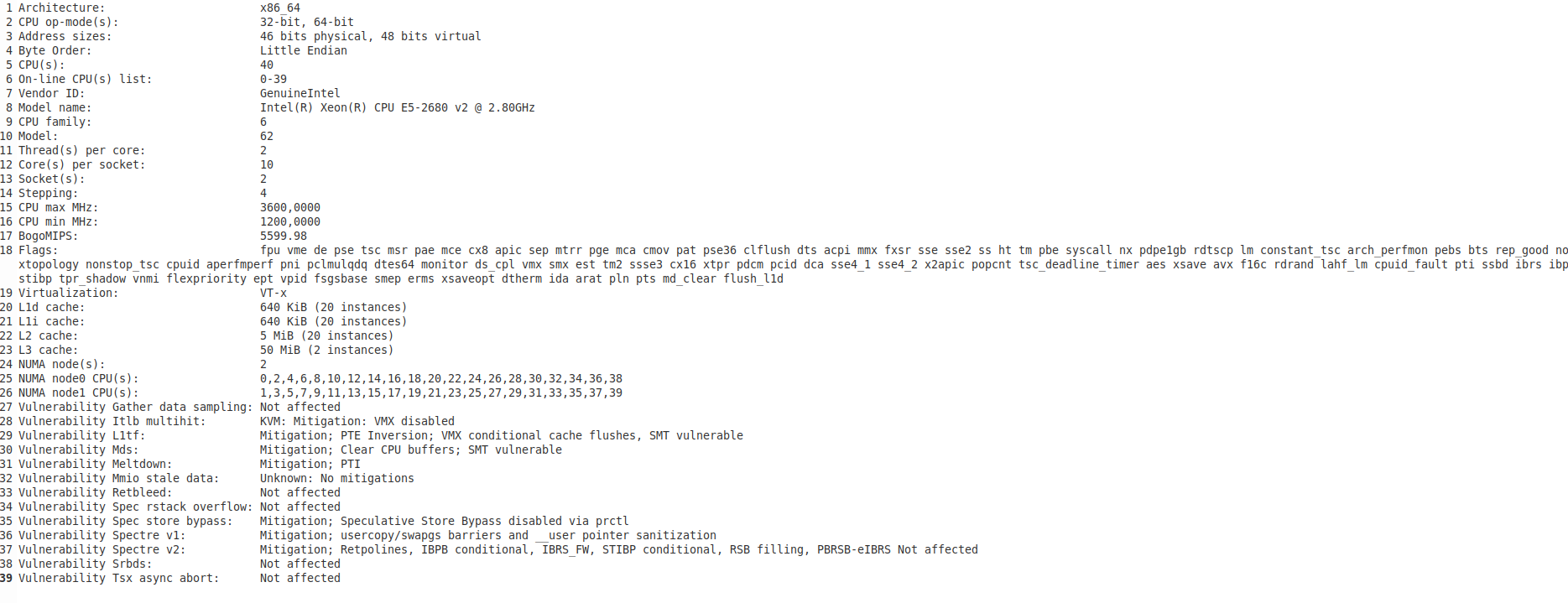
Test of CasparCG server (v2.4.0-beta1) are executed on two-socket server with 20 cores(40 threads) and two GPUs Quadro M4000 - 8GB ram.
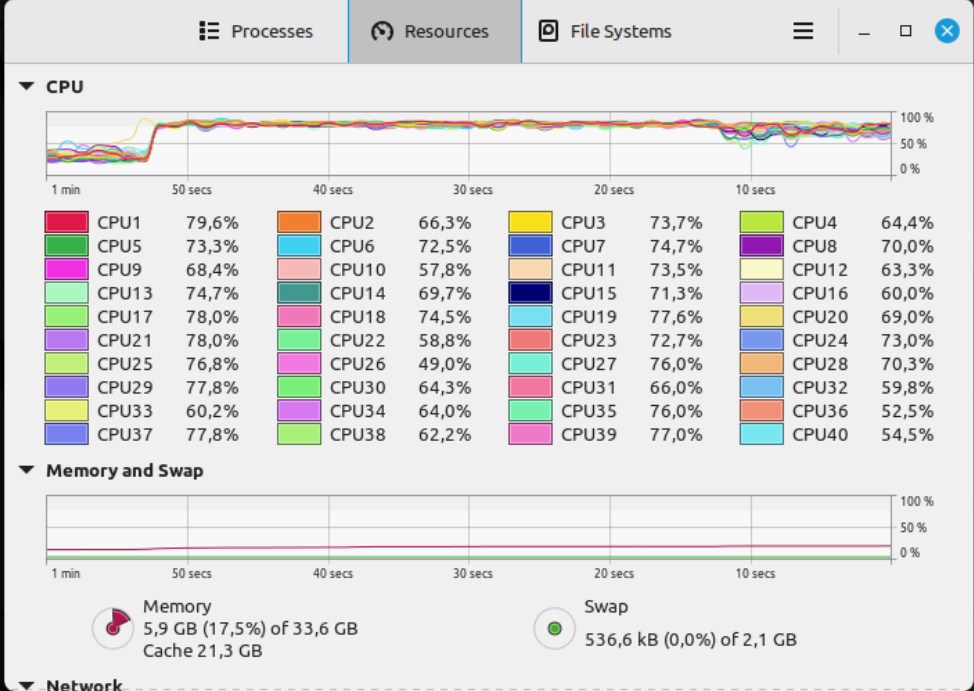
Once the server is started with default configuration - CPUs are close to 0% utilization.
Add one udp multicast stream with arguments: -format mpegts -codec:v h264_nvenc -codec:a aac - all 40 CPUs have usage of around 35-40% and one of the GPU is used for the stream encoding with around 10% utilization.
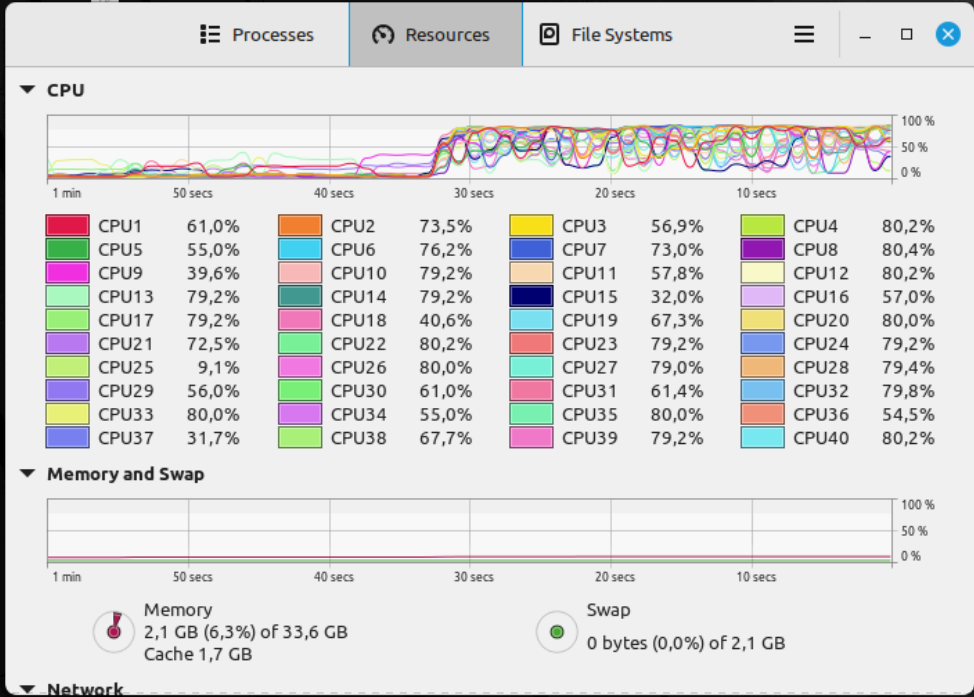
PLAY a mp4 clip - all 40 CPUs have usage of above 85% and GPU continues to encode with around 10% utilization.
All I can say on this is that I agree that those numbers seem high.
But also I am not sure how well caspar runs on machines dual socket or dual gpu machines. It has not been written with machines like this in mind, so it would not surprise me if it performs terribly due to memory constantly being in the ‘wrong’ place (ie local to the other cpu, causing accesses to be really inefficient). I have no data to prove or disprove anything though.
For compositing, we always use just the ‘first’ gpu. I don’t know how ffmpeg will choose the gpu to use for encoding/decoding on.
I have Caspars (currently sill 2.0.7 but that changes soon) running on dual CPU / dual GPU machines. I found, that it works best, when running multiple instances of the Caspar server. Use different ports to control them independently. Somehow Windows distributes the available CPU’s and GPU’s to the different server instances, so that it runs quite good that way.
I am running CasparCG server under linux from docker, starting it with two consumers and no files for play. I have a requirement to provide 8Mb/s bandwidth.
The initial CPU usage was reduced from 35-40% to 25% installing lastest oneTBB version.
Once a clip for the fist channel is played the CPUs go up to 85% and the bandwidth goes down to 5Mb/s. Once a clip is added for the second channel the CPUs started somehow to oscillate around 80% and the bandwidth goes down to 3Mb/s.
Specifying cpuset in the docker from one node only doesn’t improve the situation.
–cpuset-cpus=0,2,4,6,8,10,12,14,16,18,20,22,24,26,28,30,32,34,36,38
Interesting thread, just my two cents to the discussion. For a test I ran an ubuntu server instance on a proxmox VM and I noticed the performance was lacking. I did not test it further and instead installed ubuntu server directly on the machine instead of proxmox. Then it performed alot better.
I would investigate if it is possible to test without docker and see if it affects performance. I would assume yes, but how much? Could it be something with GPU passthrough to the docker container?
For running on ubuntu without docker, I have been exploring providing a ppa for installing casparcg. CasparCG : “CasparCG” team it has usable build of 2.4.0-beta1 currently available.
I’m not 100% finished on that ppa (might restructure/rename/rearrange packages), but it does work currently
I am also interested in how the package is used. I have only been able to start the server on an ubuntu server via blackbox with rxvt-unicode. Since caspar must have X11 information.
Though I have a custom manager around the server that starts both the server and scanner and provides me with a simple api to restart the server remotely and change the config etc. So maybe I cannot apply this package as easily.
A headless ubuntu-caspar server in my mind and deployment is the most convenient way.
This package doesn’t provide any help with starting/stopping so far, it just provides the executable and ensures all needed dependencies are installed.
It uses whatever ffmpeg is installed on the system. It looks like ffmpeg -encoders includes nvenc, so I expect that it will work.
I expect that you can use this ppa, and change your manager to invoke the executable it installs instead.
That is a good point that the scanner should also be a package available here.
But yeah, because of the requirement for X11 (when I last checked, this was very hard to remove as CEF also required it) I am not sure how best to launch it. So for now these packages are leaving that up to the user.
If would be interesting to see what people are doing to solve launching
I have tested the provided ppa version of the CasparCG server, and the behavior is absolutely same as the listed one above.
On the other side, same test was done on a single socket AMD CPU with two GPUs and this issue is not observed and behavior of the server is as expected.
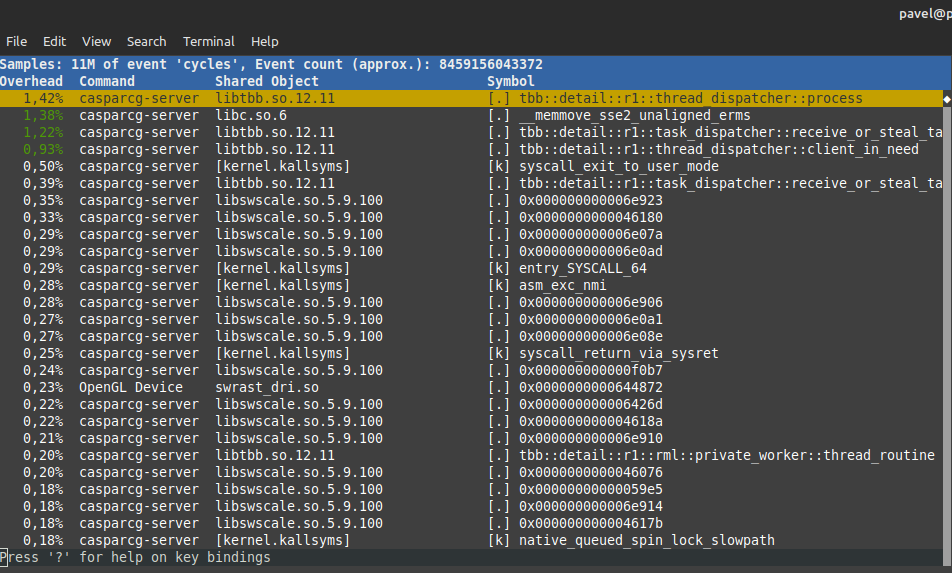
My assumptions are that tbb::parallel_for and tbb::parallel_invoke usages in the server cause this CPUs overhead, moreover there was such an CasparCG issue in the server and one of the feedback was that removing parallel operations solves the problem. On the other side there is still open oneTBB issue for high CPU usage.
Do you think using another alternative to oneTBB is a good idea?
Do you have in mind some code optimization in the parallel part that could help?
How did you manage to use nvidia-xconfig? What did you do differently. Is it running inside docker? What do you mean the x-server is no accessible? Not able to RDP into?
Very interesting that you managed to solve it. Providing a little more detail would probably help the next person with a similar issue immensly
The issue with high cpu usage came from the fact that mixing, which is using X11 server, was done with CPUs rather than with GPU(s), because of missing xorg.conf file. The nvidia-xconfig generates xorg.conf, of course you can write it on your own, where the most important step is on Device declaration where you say which card to use for the mixing.